Introduction 本篇博客的内容是C++学习过程的记录,主要参考资料和帮助工具包括:
阅读需求:需要一定的C语言基础和编程常识。
每条语句独占一行
每个函数都有一个开始和结束的花括号,并且独占一行
函数中的语句都相当于花括号缩进
与函数名相关的花括号周围没有空格
C++ 起源 上世纪八十年代贝尔实验室的Bjarne Stroustrup对C语言进行了扩充,最早叫C with Classes,名称C++来自C语言中的自增自减符++,名称C++即表明它是C的扩充版本。随着C++的发展,也对ANSI C的标准产生了影响。
Stroustrup编写的The Programming Language包含65页的参考手册,它成了最初的C++事实标准。
为了提高C++的可移植性、兼容性,1990年美国国家标准局ANSI开始着手制定C++标准,国际标准化组织ISO很快通过自己的委员会加入行列,创建联合组织ANSI/ISO,致力于制定C++标准。
第一个国际标准ISO/IEC 14882:1998于1998年获得ISO、IEC、ANSI的批准,该标准常被称为C++98.该标准不仅描述了已有的C++特性,还添加了异常、运行阶段类型识别RTTI,模版、标准模版库STL。
委员会于2003年批准了ISO/IEC 14882:2003标准,主要是订正了错误、减少多义性,并没有改变语言特性,被称为C++03,由于没有改动特性常使用C++98表示C++98/C++03。
委员会于2011年批准了ISO/IEC 14882:2011标准,C++11标准的目标是消除不一致性。
C++是如何工作的 一段C++代码示例 1 2 3 4 5 6 7 8 9 #include <iostream> int main () std::cout << "hello world!" << std::endl; std::cin.get (); }
怎么从C++源代码转换成二进制文件(机器码)? 简单的说就是编译、连接、执行三步:
step1 : 将iostream文件中的内容拷贝到代码文件中step2 : 编译器将.cpp文件编译为object file(.obj)step3 : 链接(link)将所有obj文件粘合到一起生成.exe文件
注:link的作用简单的说就是帮助在多文件项目中寻找函数
编译器是如何工作的 最初Stroustrup使用的编译器(C front end),是从C++转换成C再生成obj代码,随着C++的发展,C++开始有独立的编译器,直接生成obj代码。
对于C++编译器来说没有文件的概念
编译的第一阶段:预处理阶段,编译之前的过程
1 2 3 4 5 int Mutiply (int a , int b ) int result = a*b; return result; #include "EndBrace.h"
编译器的模式和速度是可以调节的,编译器在编译的过程中会生成额外的部分帮助你debug,返回更多的错误信息。有些时候设置编译器debug状态下的最大化速度,会自动帮你优化代码。
连接器是如何工作的 build一个项目是编译+连接的过程
linker帮助我们寻找相同类型、函数名、变量、返回参数的函数,找不到就会报错
使用CMake C++工程文件
Visual Studio IDE MSVC编译器下可以不用CMake
不同的IDE所集成的make工具所遵循的规范和标准都不同,也就导致其语法、格式不同,也就不能很好的跨平台编译,会再次使得工作繁琐起来,那么cmake为了解决这个问题而诞生了,其允许开发者指定整个工程的编译流程,在根据编译平台,生成本地化的Makefile和工程文件,最后用户只需make编译即可。
使用过程 针对已有的源代码可以编写CMakeLists.txt文件,此文件会被CMake工具解析生成相应的CMakeFiles CMakeCaches.txt cmake_install.cmake等等配置文件。
当然也可以在写代码之前直接使用VSCode中CMake的Quark Stark快速配置,会创建build目录并生成以上文件。
省略了camke的配置过程
使用cmake命令解析(更新)构建系统,过程中会生成以上文件
执行make命令编译项目
如果有更多需求可以更改CMakeLists.txt中的配置函数,比如下方所示需要配置多个源文件1 2 3 4 5 6 7 8 9 # CMake 最低版本号要求 cmake_minimum_required (VERSION 2.8) # 项目信息 project (Demo2) # 查找当前目录下的所有源文件 # 并将名称保存到 DIR_SRCS 变量 aux_source_directory(. DIR_SRCS) # 指定生成目标 add_executable(Demo ${DIR_SRCS})
常用的CMake命令: Generate a Project Buildsystem1 2 3 cmake [<options>] <path-to-source> cmake [<options>] <path-to-existing-build> cmake [<options>] -S <path-to-source> -B <path-to-build>
1 cmake --build <dir> [<options>] [--<build-tool-options>]
1 cmake --install <dir> [<options>]
1 cmake [{-D <var>=<value>}...] -P <cmake-script-file>
1 cmake -E <command> [<options>]
1 cmake --find-package [<options>]
C++头文件 头文件中的#pragma once是一个预处理指令,它通常用于防止头文件被重复包含。
在C++中,头文件通常用于存放函数、类、变量和常量等声明,以便在多个源文件中共享它们。当源文件包含一个头文件时,编译器将包含的头文件内容复制并插入到源文件中,以便在编译时处理。如果多个源文件都包含了相同的头文件,则会导致重复定义,这将导致编译器出现错误。
<>或””来指定包含的文件的位置。的示例:
“”用于包含用户自定义的头文件,编译器将从当前源文件所在的目录开始搜索该文件。
例如,以下是包含自定义头文件myheader.h的示例:
如果在当前源文件所在的目录中找不到所需的头文件,则编译器将从指定的系统路径中搜索它。
通常,使用<>来包含系统头文件,而使用””来包含自定义头文件,以避免头文件重名的问题。
需要注意的是,在实践中,使用””包含系统头文件和使用<>包含自定义头文件是可能的,但不建议这样做,因为这可能会导致代码可移植性的问题。
debug and release debug模式下编译器会做很多额外的事情帮助你调试程序
Visual Studio 设置
VS创建项目会生成一个项目文件夹和一个解决方案.sln文件(本质是一个目录性质的文本文件),项目文件夹中会有.vcxproj(本质是一个XML文档)。
VS自己建立的过滤器视图,是一种虚拟的管理视图,并不会真的在文件目录中那样储存,过滤器的虚拟视图和磁盘上的实际的文件目录没关系。
建议自己点击 解决方案资源管理器-显示所有文件-右键项目文件添加-新建文件夹,自己建立一个名为source或者 src用于管理自己创建的源代码文件、头文件等等文件,用以区别项目文件和可能使用的任何其他资源。
debug模式build项目的过程中,默认会把生成两个名为debug的文件,一个是包含编译过程的中间文件在项目文件夹内,另一个是生成的可执行文件在与项目文件夹并列在根目录中。
Output Directory: $(SolutionDir)bin\$(Platform)\$(Configuration)\Intermediate Directory: $(SolutionDir)bin\intermediates\$(Platform)\$(Configuration)\bin文件下,将中间文件放在bin\intermediates文件下
C++变量 不同变量的唯一区别本质是大小
条件分支、循环、控制流语句 if语句速度不快,不建议多用
C++指针(*) 高端理解(:dog:) : 指针是一个整数,一种储存内存地址的数字。请暂时忘掉哪些所谓的数据类型,不过是以不同字节大小存储的数字,类型只是为了让编程更容易而创造的某种虚构,类型没有意义。
空指针:void指针是一种通用指针类型,可以指向任何类型的数据
C++引用(&) 高端理解(:dog:) : 引用只是指针的伪装,只是指针的语法糖。
这段代码定义了一个名为 a 的整型变量,初始化为 5。接下来,又定义了一个名为 ref 的整型引用,并将其绑定到 a 上。
引用是一个别名,它提供了对变量的另一个名称。在这个例子中,ref 是 a 的引用,因此 ref 和 a 实际上指向同一个整型变量。因此,当我们修改 ref 的值时,实际上是修改了 a 的值,反之亦然。
1 2 3 4 5 6 7 8 9 10 11 #include <iostream> int main () int a = 5 ; int & ref = a; ref = 2 ; std::cout>>a>>std::endl; std::cin.get (); }
通过引用,我们可以避免在代码中频繁地使用指针或副本,从而提高代码的可读性和效率。在C++中,引用是一种非常有用的特性,可以用于传递函数参数、返回值和对变量的别名操作等场景。
1 2 3 4 5 6 7 void swap (int & x, int & y) int temp = x; x = y; y = temp; } int a = 5 , b = 10 ;swap (a, b);
C++类 C++ Class和Struct的区别 类定义
Cherno:
一段类代码的示例,很烂,但是帮助你学习逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <iostream> class Log { public : const int LogLevelError = 0 ; const int LogLevelWarning = 1 ; const int LogLevelInfo = 2 ; private : int m_LogLevel = LogLevelInfo; public : void SetLevel (int level) { m_LogLevel = level; } void Info (const char * message) { if (m_LogLevel >= LogLevelInfo) std::cout << "[INFO]:" << message << std::endl; } void Error (const char * message) { if (m_LogLevel >= LogLevelError) std::cout << "[ERROR]:" << message << std::endl; } void Warn (const char * message) { if (m_LogLevel >= LogLevelWarning) std::cout << "[WARNING]:" << message << std::endl; } }; int main () Log log; log.SetLevel (log.LogLevelWarning); log.Warn ("Hello!" ); log.Info ("Hello!" ); log.Error ("Hello!" ); std::cin.get (); }
内存中的区域 栈区
C++ static 静态和非静态是编程中的两个概念,带有static关键词的就是静态的。static有两种含义,一种是在类或结构体外部使用static关键字,另一种是在类或函数内部。
类外的static 类外的static,意味着链接只在内部,只能对你定义它的翻译单元可见。另一个翻译单元会忽略有static关键词的变量或函数。
类里的static 类中的static,意味着该变量实际上将与类的所有实例共享内存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> struct Entity { int x,y; void Print () { std::cout << x << "," << y << std::endl; } }; int main () Entity e; e.x = 2 ; e.y = 3 ; Entity e1 = {5 ,8 }; e.Print (); e1.Print (); std::cin.get (); }
静态成员变量在编译时存储在静态存储区,即定义过程应该在编译时完成,因此一定要在类外进行定义,但可以不初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> struct Entity { static int x,y; void Print () { std::cout << x << "," << y << std::endl; } }; int Entity::x;int Entity::y;int main () Entity e; e.x = 2 ; e.y = 3 ; Entity e1; e1.x = 5 ; e1.y = 8 ; e.Print (); e1.Print (); std::cin.get (); }
cherno:比如你有一条信息,想要在所有Entity实例间共享数据,或者将它实际存储在Entity类中,static是有有意义的。想要组织好的代码,最好在类中创建一个静态变量,而不是一些静态的或全局的东西到处乱放。
总结:静态成员是指在类中使用static关键字定义的成员,它属于类,不属于对象,可以直接使用类名调用。而非静态成员则是指没有使用static关键字定义的成员,它属于对象,只能通过对象名来调用。
静态成员属于类,不属于对象;非静态成员属于对象,不属于类。
静态成员可以直接使用类名调用;非静态成员只能通过对象名来调用。
静态成员在内存中只有一份拷贝,被所有对象共享;非静态成员在每个对象中都有一份拷贝。
静态成员可以在没有创建任何对象的情况下被访问;非静态成员必须在创建了对象之后才能被访问。函数中的static(local static) 声明一个变量时,我们需要考虑变量的作用域和生命周期。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> void function () a++; std::cout << a << std::endl; } int main () for (int i=0 ;i<5 ;i++) { function (); } std::cin.get (); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> class Singleton { public : static Singleton& Get () { static Singleton instance; return instance; } void Hello () { std::cout<<"hello" <<std::endl; } }; int main () Singleton::Get ().Hello (); std::cin.get (); }
C++ 枚举 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <iostream> class Log { public : enum Level { LevelError=0 ,LevelWarning,LevelInfo }; private : Level m_LogLevel = LevelInfo; public : void SetLevel (Level level) { m_LogLevel = level; } void Error (const char * message) { if (m_LogLevel >= LevelError) std::cout << "[ERROR]:" << message << std::endl; } void Warn (const char * message) { if (m_LogLevel >= LevelWarning) std::cout << "[WARNING]:" << message << std::endl; } void Info (const char * message) { if (m_LogLevel >= LevelInfo) std::cout << "[INFO]:" << message << std::endl; } }; int main () Log log; log.SetLevel (Log::LevelError); log.Warn ("Hello!!" ); log.Info ("Hello!!" ); log.Error ("Hello!!" ); std::cin.get (); }
C++ <>操作符 在 C++ 中,<>符号通常用于指定模板参数类型。在模板的定义和使用中,我们使用<>符号将模板参数列表括起来,以指定模板的具体类型。
1 2 3 4 template <typename T>class MyClass { };
在这里, 中的<>符号表示这是一个模板参数列表,其中typename T表示模板参数类型为T。<>指定其类型
C++ 函数 函数类型 构造函数 一种特殊类型的方法,这是一种每次你构造一个对象时都会调用的方法,用以帮助初始化类。
1 2 3 4 5 6 7 8 9 10 11 12 class Entity { public : { float x,y; Entity () { x = 0.0f ; y = 0.0f ; } } }
当用new关键词生成一个对象的时候,编译器会自动提供一个构造函数,如果你想删除它,可以用delete关键词
1 2 3 4 5 6 class log { private : log ()=delete ; static void write () };
构造函数的初始化成员列表 构造函数中的函数名后加:,添加成员,每调用这个函数会执行一次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> class Example { public : Example () { std::cout << "Created Entity" << std::endl; } Example (int x) { std::cout << "Created Entity" << x << std::endl; } }; class Entity { private : std::string m_Name; Example m_Example; public : Entity () { m_Name = std::string ("Unknown" ); m_Example = Example (8 ); } Entity (const std::string& name) :m_Name (name) { } }; int main () Entity e0; }
析构函数 destructor 析构函数,帮助你销毁对象,清理内存的东西。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <iostream> class Entity { public : float X,Y; Entity () { X = 0.0f ; Y = 0.0f ; std::cout<<"Created Entity" <<std::endl; } ~Entity () { std::cout<<"Destoryed Entity" <<std::endl; } void print () { std::cout<< X <<"," << Y <<std::endl; } }; void Function () Entity e; e.print (); e.~Entity (); } int main () Function (); std::cin.get (); }
继承 待补充
虚函数 Virtual Function 首先:强调一个概念
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class A { public : virtual void foo () { cout<<"A::foo() is called" <<endl; } }; class B :public A{ public : void foo () { cout<<"B::foo() is called" <<endl; } }; int main (void ) A *a = new B (); a->foo (); return 0 ; }
这个例子是虚函数的一个典型应用,通过这个例子,也许你就对虚函数有了一些概念。它虚就虚在所谓”推迟联编”或者”动态联编(Dynamic Dispatch)”上,一个类函数的调用并不是在编译时刻被确定的,而是在运行时刻被确定的。由于编写代码的时候并不能确定被调用的是基类的函数还是哪个派生类的函数,所以被成为”虚”函数。
C++接口(纯虚函数)Pure Virtual Function C++的接口其实就是一个类,并没有interface关键词。
纯虚函数是在基类中声明的虚函数,它在基类中没有定义,但要求任何派生类都要定义自己的实现方法。在基类中实现纯虚函数的方法是在函数原型后加 =0:
1 virtual void funtion1 () 0
C++访问修饰符
cherno:可见性是让代码更容易维护、理解,不管是阅读代码还是扩展代码,这与性能无关,也不会产生完全不同的代码,可见性不是CPU层面需要理解的东西,只是人发明的概念,为了帮助其他人和自己。
C++数组
数组下标的神奇理解:多数编程语言的数组下标是从0开始的,可以把它理解为对内存起始地址的‘偏移 ’
用new关键字生成(堆上创建)的数组将会一直在内存中存在直到你删除它。
array类创建数组 1 2 #include <array> std::array<int ,5> another;
C++字符串 C++字符串字面量 String Literal String Literal
C++ const
Cherno:const是我喜欢称之为伪关键字的东西,因为它在改变生成代码方面做不了什么。它有点像类和结构体的可见性,这只是一个机制让我们的代码更干净,并对开发人员写代码强制特定的规则。
const与指针 如果唯一的 const 位于符号的左侧,表示指针所指数据是常量,数据不可变 的右侧,表示指针本身是常量,指针不能指向其他内存地址
1 2 const int * a = new int ; int const * a = new int ;
类中的const 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> class Entity { private : int * m_X,*m_Y; public : const int * const GetX () const { return m_X; } void SetX (int x) { m_X = x; } }; int main () std::cout << "Hello, World!\n" ; return 0 ; }
常量对象只能调用常量函数
C++ mutable 2种用法
C++ 三元操作符 三元操作符一般比if else语句更快
C++ 创建对象与初始化 即使一个空类什么也没有,创建一个对象也要占用至少1个字节的内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 using String = std::string;class Entity { private : String m_Name; public : Entity () :m_Name ("Unknown" ){} Entity (const String& name) :m_Name (name){} const String& GetName () const return m_Name;} }; int main () Entity* entity = new Entity ("Odrin" ); std::cout << entity.GetName () << std::endl; }
C++ new new的本质
1 2 Entity* e = new Entity (); Entity* e = (Entity*)malloc (sizeof (Entity));
C++ 隐式转换与explicit 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Entity { private : std::string m_Name; int m_Age; public : Entity (const std::string& name) :m_Name (name),m_Age (-1 ){} Entity (int age) :m_Name ("Unkown" ),m_Age (age){} }; void PrintEntity (const Entity& entity) std::cout<<"Entity" <<std::endl; } int main () Entity b = 22 ; PrintEntity (Entity ("Odrin" )) }
此外还有强制转换cast
运算符及其重载 当我们需要用到运算符重载时,往往是类中的一种特殊类型需要处理或者类本身需要处理。operator关键字重载操作符
1 2 3 4 std::ostream& operator <<(std::string& stream, const Vector2& other) { stream << other.x << "," << other.y ; }
C++ this关键字 this是一个指向当前对象实例的指针,该方法属于这个对象实例。
对象的生存周期(栈作用域) 一般的初始化是在栈上分配的,new是在堆上分配的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Entity { public : float X,Y; Entity () { X = 0.0f ; Y = 0.0f ; std::cout<<"Created Entity" <<std::endl; } ~Entity () { std::cout<<"Destoryed Entity" <<std::endl; } }; class ScopedPtr () private : Entity* m_ptr; public : ScopedPtr (Entity* ptr) :m_ptr (ptr) { } ~ScopedPtr (Entity* ptr) { delete m_ptr; } }; int main () { ScopedPtr e = new Entity (); } std::cin.get (); }
C++ 智能指针 new在堆上分配内存,detele删除内存,智能指针是一种帮助你实现这一过程自动化的方式。
unique_ptr
1 std::unique_ptr<Entity> entity = std::make_unique <Entity>();
shared_ptr
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Entity { Entity () { std::cout<<"Created Entity" <<std::endl; } ~Entity () { std::cout<<"Destoryed Entity" <<std::endl; } }; int main () { std::shared_ptr<Entity> e0; { std::shared_ptr<Entity> sharedEntity = std::make_shared <Entity>(); e0 = sharedEntity; } } }
weak_ptr
1 2 3 4 5 6 7 8 9 10 int main () { std::shared_ptr<Entity> e0; { std::shared_ptr<Entity> sharedEntity = std::make_shared <Entity>(); e0 = sharedEntity; } } }
C++ 友元函数 在 C++ 中,友元函数(friend function)是一种特殊的函数,可以访问类中的私有成员和受保护成员,即使它们不是类的成员函数。这样,友元函数可以扩展类的功能,同时保护类的封装性。
1 2 3 4 5 6 7 8 9 class MyClass {public : private : int x; friend void myFriendFunc (MyClass& obj) };
在上面的代码中,myFriendFunc是一个友元函数,可以访问 MyClass 的私有成员 x。在函数声明中,使用friend关键字将该函数声明为 MyClass 的友元函数。
当需要访问一个类的私有成员时,但又不希望将该成员变成公有成员时,可以使用友元函数。
当需要两个或多个类互相访问对方的私有成员时,可以使用友元函数。
C++ 复制与拷贝构造函数 一个基本的String类中的浅拷贝过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <iostream> #include <string> class String { private : char * m_Buffer; unsigned int m_Size; public : String (const char * string) { m_Size = strlen (string); m_Buffer = new char [m_Size+1 ]; memcpy (m_Buffer,string,m_Size+1 ); } ~String () { delete [] m_Buffer; } char & operator [](unsigned int index) { return m_Buffer[index]; } friend std::ostream& operator <<(std::ostream& stream,const String& string); }; std::ostream& operator <<(std::ostream& stream,const String& string) { stream << string.m_Buffer; } char & operator [](unsigned int index) { return m_Buffer[index]; } int main () String string = "Odrin" ; String second = string; second[2 ] = 'a' ; std::cout << string << std::endl; std::cout << second << std::endl; std::cin.get (); }
想要达到“深拷贝”的效果,即复制整个对象,就需要拷贝构造函数
1 2 3 4 5 String (const String& other) :m_Buffer (other.m_Buffer),m_Size (other.m_Size) { }
自己构造一个“深拷贝”拷贝函数
1 2 3 4 5 6 7 8 9 10 String (const String& other) :m_Size (other.m_Size) { m_Buffer = new char [m_Size + 1 ]; memcpy (m_Buffer,other.m_Buffer,m_Size+1 ); }
但是当拷贝函数被多次调用时候,又会有浪费内存的现象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void PrintString (String string) std::cout << string << std::endl; } int main () String string = "Odrin" ; String second = string; second[2 ] = 'a' ; PrintString (string); PrintString (second); std::cin.get (); }
如何解决这个问题,可以修改PrintString函数的参数,通过const reference的方式去传递对象
1 2 3 4 5 6 7 8 9 void PrintString (const String& string) std::cout << string << std::endl; }
如果你想要禁用拷贝构造函数(类似unique_ptr),可以这样:
1 String (const String& other) = delete ;
C++ 箭头操作符 -> 1 2 3 4 5 6 7 8 9 10 class Entity { void Print () const }; int main () Entity e; Entity* ptr = &e; prt -> Print (); }
C++ 动态数组 vector vector并不是指向量这个字面意思,它更像一个不强制其实际元素有唯一性的集合。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> #include <string> #include <vector> struct Vertex { float x,y,z; }; std::ostream& operator <<(std::ostream& stream,const Vertex& vertex) { stream << vertex.x << "," << vertex.y << "," << vertex.z ; return stream; } int main () std::vector<Vertex> vertices; vertices.push_back ({1 ,2 ,3 }); vertices.push_back ({4 ,5 ,6 }); for (int i = 0 ; i < vertices.size ();i++) { std::cout << vertices[i] << std::endl; } vertices.erase (vertices.begin ()+1 ); for (Vertex& v : vertices) { std::cout << v << std::endl; } std::cin.get (); }
C++ std::vector优化 vector一般比较慢
以下代码会展示两个优化点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <iostream> #include <string> #include <vector> struct Vertex { float x,y,z; Vertex (float x,float y,float z) : x (x),y (y),z (z) { } Vertex (const Vertex& vertex) : x (vertex.x),y (vertex.y),z (vertex.z) { std::cout << "Copied!" << std::endl; } }; int main () std::vector<Vertex> vertices; vertices.push_back (Vertex (1 ,2 ,3 )); vertices.push_back (Vertex (4 ,5 ,6 )); vertices.push_back (Vertex (7 ,8 ,9 )); std::cin.get (); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ```emplace_back()```方法,只传递构造函数的参数列表,并不执行,省去从vertex到vector的复制 优化后代码: ```cpp int main() { std::vector<Vertex> vertices; vertices.reserve(5); //优化了第2、3、4、5句扩容过程中产生复制 vertices.emplace_back(1,2,3); //0 扩容复制次数 vertices.emplace_back(4,5,6); //1 vertices.emplace_back(7,8,9); //2 vertices.emplace_back(10,11,12); //0 vertices.emplace_back(13,14,15); //4 std::cin.get(); } /* 无输出了 */
此外,注意到扩容复制的次数分别是0,1,2,0,4,进行多次实验后发现vector需要扩容时,以2的x次方扩容,x为已经扩容的次数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 vertices.emplace_back (1 ,2 ,3 ); vertices.emplace_back (4 ,5 ,6 ); vertices.emplace_back (7 ,8 ,9 ); vertices.emplace_back (10 ,11 ,12 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 ); vertices.emplace_back (13 ,14 ,15 );
C++ 使用静态库 示例链接二进制库,GLFW Binary Library
库通常包含两部分includes和library,即包含目录和库目录。
静态库文件glfw3.lib
静态链接是在编译时被链接的,意味着这个库会被放进你的可执行文件中,它在你的.exe文件中。
静态链接在技术上更快,因为编译器或链接器实际上可以执行链接时优化之类的。
cherno:静态库使用过程:头文件提供声明,告诉我们哪些函数是可用的,然后库文件为我们提供了定义,这样我们就可以链接到那些函数,并在C++中调用函数时使用正确的代码。
C++ 使用动态库 cherno留了个问题 动态库文件:glfw3dll.lib、glfw3.dll前者是一堆指向后者的指针。
1 2 3 4 5 6 7 8 9 10 11 #include <iostream> #include <GLFW/glfw3.h> int main () int a = glfwInit (); std::cout << a << std::endl; std::cin.get (); }
C++ templates 模版的作用,有点类似于元编程meta programming
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <iostream> #include <string> template <typename T> void Print (T value) std::cout << value << std::endl; } int main () Print (5 ); Print ("hello" ); Print (5.5f ); std::cin.get (); }
模版的小技巧,因为模版会在编译期被evaluate,而声明一个数组需要知道具体的大小,模版可以很好的解决这个问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <iostream> #include <string> template <typename T,int N>class Array { private : T m_Array[N]; public : int GetSize () const return N;} }; int main () Array<std::string,50 > array; std::cout << array.GetSize () << std::endl; std::cin.get (); }
栈与堆内存比较 栈通常是一个预定义大小的内存区域,2MB左右
在栈上分配的距离内存更近,他们可以更方便的放入CPU缓存线(CPU Cache的最小单位)上
在堆上分配的,可能会是一些cache miss(CPU要访问的数据,在Cache中有,称为hit,没有称为miss),对于cache miss的情况,通常数量不大,可以忽略不计
两种分配最大的区别,是堆分配的慢
栈分配 汇编
C++ 宏 宏定义发生在编译前,实际上做的是改变了文本生成的方式。也是一个复制替换的过程
1 2 3 4 5 6 7 8 9 #include <iostream> #include <string> #define WAIT std::cin.get() int main () char a = WAIT; std::cout << a << std::endl; }
一般在记录系统日志的时候使用
1 2 3 4 5 #ifdef PR_DEBUG #define LOG(X) std::cout << x << std::endl; #else #define LOG(X) #endif
C++ auto 自动识别变量类型的关键字
1 2 3 4 5 6 7 8 9 for (std::vector<std::string>::iterator it = strings.begin (); it != strings.end ();it++){ std::cout << *it << std::endl; } for (auto it = strings.begin (); it != strings.end ();it++){ std::cout << *it << std::endl; }
C++ 静态数组 std::array std::array和C语言风格的数组哪个好用呢?
1 2 3 4 5 6 7 8 9 #include <iostream> #include <array> int main () std::array<int ,4> data; data[5 ] = 2 ; int dataOld[5 ]; dataOld[5 ]=0 ; }
C 函数指针 函数指针是将一个函数赋值给一个变量的方法,目的就是使函数参数化
函数其实就是CPU指令,当我们编译代码时,函数就在二进制文件当中的某个地方,函数指针其实就是获取了函数的地址。
1 2 3 4 5 6 7 8 9 10 11 12 #include <iostream> void HelloWorld (int a) std::cout << "Hello World!" << a << std::endl; } int main () auto function = HelloWorld; function (5 ); std::cin.get (); }
上述函数指针也可以写成
1 2 3 4 5 int main () void (*function)(int ) = HelloWorld; std::cin.get (); }
一个实际更体现函数指针作用的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> #include <vector> void PrintValue (int value) std::cout << "Value:" << value << std::endl; } void ForEach (const std::vector<int >& values,void (*func)(int )) for (int value : values) func (value); } int main () std::vector<int > values = {1 ,5 ,4 ,2 ,3 }; ForEach (values,PrintValue); std::cin.get (); }
C++ 匿名函数 lambda —-待续
Cherno:lambda就像是一个快速的一次性函数,展示下需要运行的代码,我们更想将它视为一个变量,而不是更像一个正式的函数那样,在我们实际编译的代码中作为一个符号那样存在。理解如何使用它和何时使用它是完全不同的事情。
为什么不使用 #using namespace std?
Cherno:方便区分是否是C++标准库的内容,因为一些大厂,比如EA,有自己的改造的模版库,叫EASTL,如果不写std::,在阅读代码时,如果遇到重名函数,你可能会迷惑它来自哪个库。此外假如不同命名空间可能有同名函数,同时使用这些库会造成调用混乱。
如果你一定要使用using namespace,请在一个小区域内。
C++ namespace 类本身也是一种命名空间
1 2 3 4 5 6 using namespace ::std;using std::cout;namespace <#name#> = <#namespace#> ;
Cherno:我认为如果是一个非常严肃的项目,你应该把代码写在namespace后面
C++ 线程 计算机可以同时执行多个进程和线程,通常一个程序一个进程(也有多个),一个进程包含多个线程,线程与进程的区别是,线程之间的内存是共享的,进程不是。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <iostream> #include <thread> static bool s_finished = false ;void dowork () using namespace std::literals::chrono_literals; std::cout << "start thread id is " << std::this_thread::get_id () << std::endl; while (!s_finished) { std::cout << "working...0" << std::endl; std::this_thread::sleep_for (1 s); } } int main () std::thread worker (dowork) ; std::cin.get (); s_finished = true ; worker.join (); std::cout << "finished" << std::endl; std::cout << "finished thread id is " << std::this_thread::get_id () << std::endl; std::cin.get (); }
C++ 计时 STD chrono库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> #include <chrono> #include <thread> struct Timer { std::chrono::time_point<std::chrono::steady_clock> start, end; std::chrono::duration<float > duration; Timer () { start = std::chrono::high_resolution_clock::now (); } ~Timer () { end = std::chrono::high_resolution_clock::now (); duration = end - start; float ms = duration.count () * 1000.0f ; std::cout << "Timer took " << ms << "ms " << std::endl; } }; void function () Timer timer; for (int i = 0 ; i < 100 ; i++) { std::cout << "hello\n" ; } } int main () function (); std::cin.get (); }
多维数组 在处理任何类型的数组时,指针是非常重要的,处理内存的简单方法是使用指针。
1 2 3 4 5 6 7 8 9 10 11 12 #include <iostream> int main () int ** a2d = new int *[5 ]; for (int i = 0 ; i < 5 ;i++) a2d[i] = new int [5 ]; for (int i = 0 ; i<5 ;i++) delete [] a2d[i]; delete [] a2d; std::cin.get (); }
此外,二维数组切换维度时有可能出现更多的cache miss,因为不同维度的内存空间是由空闲列表分配的,可能并不连续。想要优化速度,可以想办法用一维数组表示二维数组。
1 2 3 4 5 6 7 8 int * array = new int [5 *5 ];for (int i = 0 ; i < 5 ;i++){ for (int j = 0 ;j < 5 ;j++) { array[x+y*5 ] = 2 ; } }
C++ 排序 学习std库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <iostream> #include <vector> #include <algorithm> int main () std::vector<int > values = { 3 ,5 ,4 ,1 ,2 }; std::sort (values.begin (), values.end (),std::greater <int >()); for (int value : values) std::cout << value << std::endl; std::cin.get (); }
C++ 类型双关 类型双关type punning,这只是个花哨的术语,用来在C++中绕过类型系统。
1 2 3 4 5 6 7 #include <iostream> int main () int a = 50 ; double value = *(double *)&a; std::cout << value << std::endl; std::cin.get (); }
在更复杂的代码中,这种处理可以减少“复制”的现象。
C++ 联合体 以下也是一种类型双关的表现,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <iostream> int main () struct Union { union { float a; int b; }; }; Union u; u.a = 2.0f ; std::cout << u.a << "," << u.b << std::endl; }
联合体使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 include <iostream> struct Vector2 { float x,y; }; struct Vector4 { union { struct { float x, y, z, w; }; struct { Vector2 a, b; }; }; }; void PrintVector2 (const Vector2& vector) std::cout << vector.x << "," << vector.y << std::endl; } int main () Vector4 vector = {1.0f ,2.0f ,3.0f ,4.0f }; PrintVector2 (vector.a); PrintVector2 (vector.b); vector.z = 500.0f ; std::cout << "----------------------" << std::endl; PrintVector2 (vector.a); PrintVector2 (vector.b); }
C++ 虚析构函数 在下列情境中,出现了内存泄漏问题,原因是在一个多态使用中没有销毁子类中开辟的内存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> class Base { public : Base () { std::cout << "Base Constructor\n" ; } ~Base (){ std::cout << "Base Destructor\n" ; } }; class Derived : public Base{ public : Derived () { m_Array = new int [5 ]; std::cout << "Derived Constructor\n" ; } ~Derived (){ delete [] m_Array; std::cout << "Derived Destructor\n" ; } private : int * m_Array; }; int main () Base* base = new Base (); delete base; std::cout << "------------------------\n" ; Derived* derived = new Derived (); delete derived; std::cout << "------------------------\n" ; Base* poly = new Derived (); delete poly; std::cin.get (); }
C++ 类型转换 cast 分为static_cast dynamic_cast reinterpret_cast const_cast
static_cast static_cast 用于进行比较“自然”和低风险的转换,如整型和浮点型、字符型之间的互相转换,不能用于指针类型的强制转换reinterpret_cast 用于进行各种不同类型的指针之间强制转换const_cast 仅用于进行去除 const 属性的转换dynamic_cast 不检查转换安全性,仅运行时检查,如果不能转换,返回null
条件与操作断点 有条件的控制断点的执行
现代C++的安全问题 安全编程:我们希望降低崩溃、内存泄漏、非法访问等问题
预编译头文件 在大型项目中,编译时间较长,预编译是减少这一时间的手段。
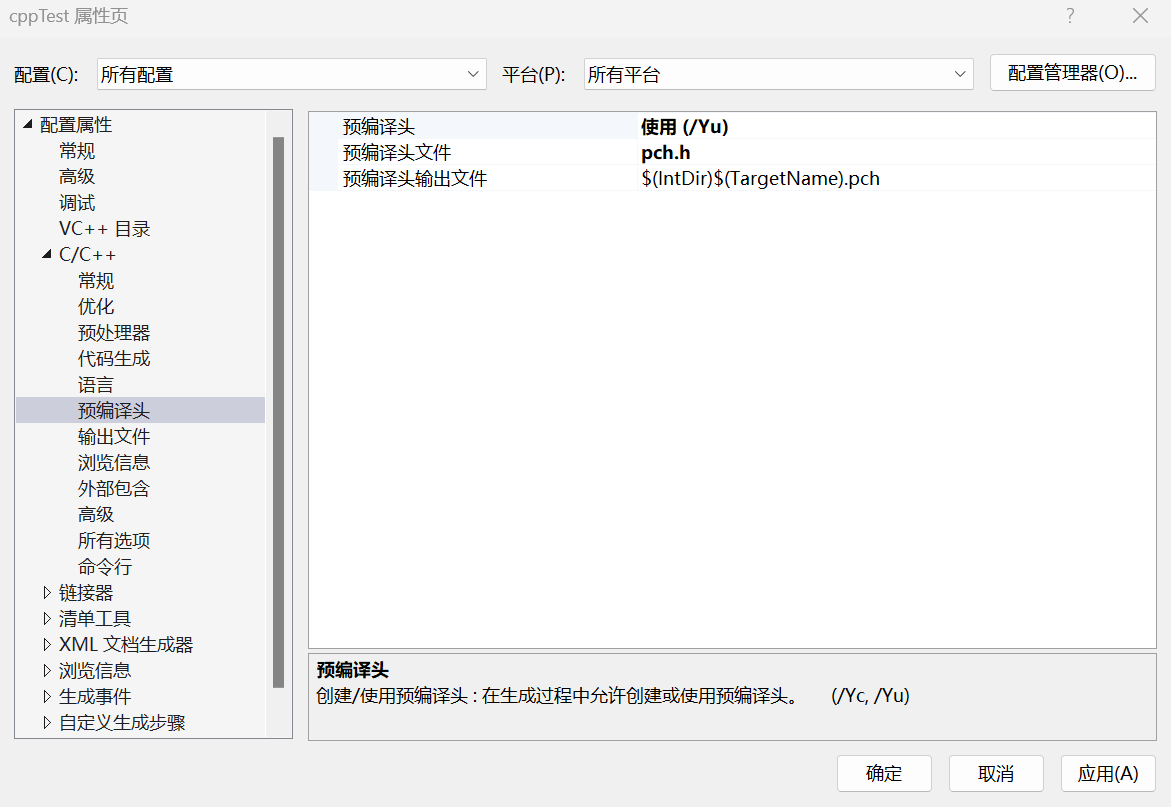
写一个main.cpp
1 2 3 4 5 6 #include "pch.h" int main () std::cout << "------------------------" << std::endl; }
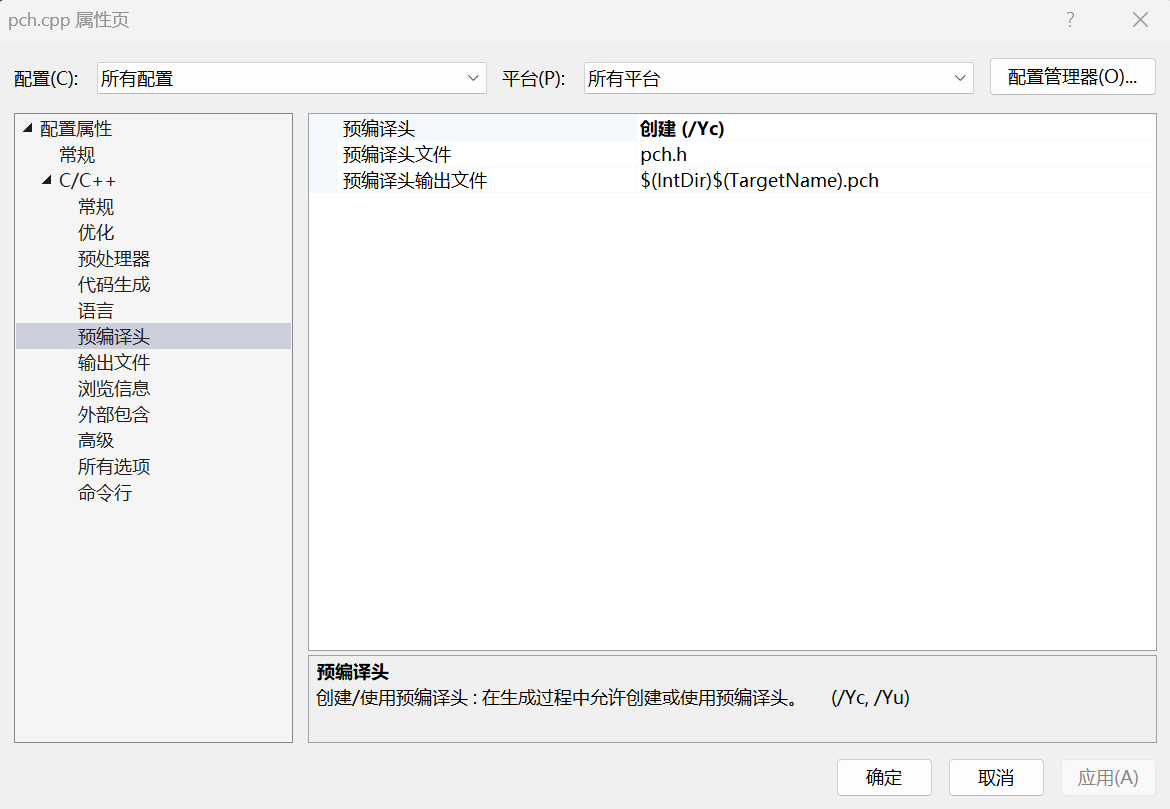
一个pch.cpp文件
一个pch.h文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #pragma once #include <iostream> #include <algorithm> #include <functional> #include <memory> #include <thread> #include <utility> #include <string> #include <stack> #include <deque> #include <array> #include <vector> #include <set> #include <map> #include <unordered_set> #include <unordered_map> #include <Windows.h>
对pch.cpp文件进行设置
在MSVC环境下的提升(也可以使用gcc测试一下,效果更显著):
1 2 3 4 5 6 //使用预编译头文件前 1>项目性能摘要: 1> 2459 毫秒 C:\Dev\cppTest\cppTest\cppTest.vcxproj 1 次调用 //使用预编译头文件后 1>项目性能摘要: 1> 1618 毫秒 C:\Dev\cppTest\cppTest\cppTest.vcxproj 1 次调用
C++ dynamic_cast C++ 基准测试 基准测试(benchmarking)其实就是一种性能测试,只不过会偏向于强调可对比性。
在VS2022的debug模式下测试,下列通过写一个计时器计时的方式是有效的。但是在release模式下,用于for循环会被优化,在编译时就会把结果计算出来,而不是运行时,所以这种测试在release模式下就失效了,根本不会进行计时。一定要确保你的测试和测试后的代码在release时是有意义的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <iostream> #include <memory> #include <chrono> class Timer { public : Timer () { m_StartTimepoint = std::chrono::high_resolution_clock::now (); } ~Timer () { Stop (); } void Stop () { auto endTimepoint = std::chrono::high_resolution_clock::now (); auto start = std::chrono::time_point_cast <std::chrono::microseconds>(m_StartTimepoint).time_since_epoch ().count (); auto end = std::chrono::time_point_cast <std::chrono::microseconds>(endTimepoint).time_since_epoch ().count (); auto duration = end - start; double ms = duration * 0.001 ; std::cout << duration << "us(" << ms << "ms)\n" ; } private : std::chrono::time_point< std::chrono::high_resolution_clock> m_StartTimepoint; }; int main () int value = 0 ; { Timer timer; for (int i = 0 ; i < 1000000 ; i++) { value += 2 ; } } std::cout << value << std::endl; __debugbreak(); }
C++ 处理多个不同类型的返回 用结构体
C++17 结构化绑定 结构化绑定是C++17以后的新特性,能让我们更好的处理多返回值问题。
C++11 新增了std::tuple容器用于构造一个元组。我们可以使用std::tie对元组进行拆包,但我们依然必须非常清楚这个元组包含多少个对象,各个对象是什么类型,非常麻烦。
C++17 完善了这一设定,给出了 结构化绑定。
之前的使用结构体的方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> #include <string> #include <tuple> struct Person { std::string Name; int Age; }; std::tuple<std::string, int > CreatePerson () return { "Odrin" , 24 }; } int main () Person p; std::tie (p.Name, p.Age) = CreatePerson (); }
结构化绑定的方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <iostream> #include <string> #include <tuple> std::tuple<std::string, int > CreatePerson () return { "Odrin" , 24 }; } int main () auto [name, age] = CreatePerson (); std::cout << name; }
C++17 如何处理OPTIONAL数据 OPTIANAL也是C++17的新特性,对有可能不存在的数据进行处理,例如你想读取一个文件但是不确定它是否存在。
1 2 3 #include <optional> std::optional<type> function (param) {statement; return type;} auto result = function ();
1: result.has_value()判断数据是否存在, 通过result.value()获取数据
C++17 单一变量存放多类型数据 VARIANT也是C++17的新特性,类似于union,type1与type2表示存储的数据类型。
1 2 3 #include <variant> std::variant<type1, type2> data; data = type1 (xxx)
读取:(data)
C++17 如何存储任意类型的数据 any和variant是类似的,都可以存储任何类型,但是variant必须列出所有类型,any则不需要。这是绝大多情况下是variant更好的原因,因为类型安全。
如何让C++运行得更快 1、为什么不能传引用?
2、std::async为什么一定要返回值?
如何让C++字符串更快 优化std:string
C++ 可视化基准测试 总结: cpp的计时器配合自制简易json配置写出类,将时间分析结果写入一个json文件,用chrome://tracing 这个工具进行可视化
C++ 单例模式 C++ 小字符串优化 跟踪内存分配的简单方法 C++ 左值与右值 C++ 持续集成 C++ 静态分析 C++ 参数计算顺序 请判断下列程序的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <iostream> void PrintSum (int a, int b) std::cout << a << "+" << b << "=" << (a + b) << std::endl; } int main () int value = 0 ; PrintSum (++value,++value); }
在MSVC的环境下结果为2+1=3,说明先传入了b,在传入了a,然而使用其他编译器,比如clang则会先传入a,在传入b,并且给出参数未排序的警告信息。
C++ 移动语义 C++ stdmove与移动赋值操作符 C++ 编写桌面程序的推荐方法 ImGUI:Dear ImGui is a bloat-free graphical user interface library for C++.